Python-first in data teams
- Before we start
- Python: the common language
- Adopting a python-first mindset
- Close second: SQL
- How about other languages?
Before we start
Before I begin, I'd like to state and explain that Python is my first language, therefore, this article will have a bias towards Python as a programming language. However, over the years, I gain experiences in many other languages and wrote ETL pipelines in both Scala and SQL as well. In fact, I even developed an SQL framework, back in the days, called SQLbucket that helped writing SQL ETL pipelines. So, I possess knowledge and experience in other data-related languages. Still, my personal preference leans towards Python, so please consider this possible bias of mine while reading the following article.
Python: the common language
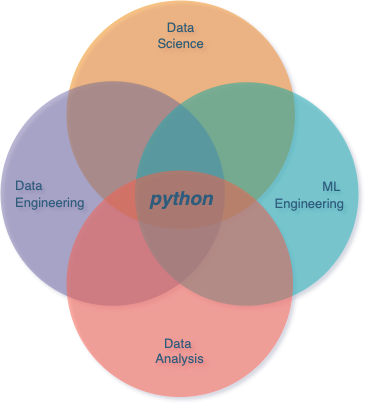
Python is a versatile language that is widely used in all data-related fields. In data science, it is a necessary skill for machine learning, statistics, and deep learning, with popular libraries such as Scikit-learn, SciPy, and Hugging Face's transformers library.
For data analysis, Pandas is the go-to library, and its robust ecosystem for data visualization is extensively utilized. Python notebooks have also gained immense popularity.
In the realm of data engineering, Python, particularly PySpark, has surpassed Scala for Spark-related tasks, and Snowpark is seeing real adoption for interacting with snowflake with Python. Additionally, data pipelines are frequently orchestrated using Python-based tools like Airflow, Prefect, Luigi, and Dagster.
For machine learning engineers, Python is indispensable for executing inferences and deploying models (trained using Python) over APIs, often with the help of Flask or FastAPI.
In essence, Python serves as a universal language across all data roles.
Adopting a python-first mindset
Any company that treats data as a critical commodity should, today, invest in making sure Python is adopted as a first citizen language in its organisation.
By ensuring Python as a must-have skill today, you are opening up opportunities for stronger collaboration between teams and data profiles, and a door for upskilling to naturally occurs within your organisation.
Adopting InnerSource
InnerSource is a methodology for software development that involves the integration of an open-source mindset and practices within a company, with the goal of enhancing collaboration and efficiency. Impulsing Python as a common language in the data teams will make contributions to repositories between teams more likely to occur, and will make team to converge naturally to an innersource model.
For instance, if a team of data engineer needs a quick feature to be added in one of the tool the data-platform team maintains, if both teams work with the same language, anyone in the data engineering team could actually make a pull request themselves to the platform team codebase. This gives various advantages in the long run:
- The platform team just got a new feature added to their codebase, with only a code review to be done.
- The platform team still remains in control by approving the pull request and merging branches.
- The data engineering team got their feature that they needed most likely faster.
- The data engineering team is now familiar with a new part in the data ecosystem of the organisation.
- If the platform team is looking for a new hire, they may look into the pool of existing data engineers that have already contributed to their projects.
Upskilling your teams
The type of Python skills vary between teams. For instance, machine learning engineers and data engineers usually have a code base that reflects a better understanding of programming concepts like object-oriented programming and unit testing. These are areas where analysts and data scientists may have had less exposure, given the nature of their work and focus.
On the other hand, data scientists and analysts are proficient in Python skills related to data analysis and machine learning ecosystems, areas where data engineers may need to improve.
There's a clear opportunity for synergy here. By sharing knowledge, both sets of employees can expand their Python skills, improving the quality and diversity of skills within the teams. This could also significantly enhance the quality of code bases. For example, if data scientists and analysts learn and apply programming concepts like object-oriented programming, unit testing, and continuous integration, it could dramatically improve the code quality.
Close second: SQL
While I advocate for a Python-first approach, I do not believe that a Python-only strategy is practical or beneficial. SQL, which has been in use for over 50 years, remains a vital tool in the data industry, and I am confident that it will continue to be so for another 50 years to come.
SQL dialects, despite their own peculiarities, are fundamentally similar. The SQL used in a Redshift cluster is comparable to the SQL used in Snowflake or a Spark cluster. SQL is the common data interface in many modern technologies, such as running SQL queries on a Kafka cluster or even on Google Sheets.
One of the most significant examples of SQL's importance in data teams is the use of the DBT framework. DBT empowers analysts to create their own ETL processes independently, without the need for a data engineer's input.
While Python is a crucial language for data teams, SQL's widespread use make it an essential skill for anyone working with data as well.
How about other languages?
Any data organisation could achieve 99% of their goals by focusing solely on Python and SQL. However, this does not mean that teams should now migrate all their scala or java processes to now Python. The context of your organisation and its history, as well as the current talent inside the company are important factors when choosing languages.
It goes without saying however that if a company were to adopt a python-first approach, and that its context permits it, it would be most likely beneficial in the short, medium and long-term.